

Virtuaaliserverin webpuolen, ja miksi muutenkin, sietokykyä ja tunnuslukuja kuormituksessa pitäisi testata aina välillä. Kaikki saattaa toimia ilman ongelmia normaalisti, mutta kun jossain vaiheessa onnistutkin julkaisemaan jotain viraalimpaa, niin ongelmia alkaakin tulla. Satunnaiset kävijät jäävät taatusti satunnaisiksi, jos he eivät saakaan haluamaansa sisältöä, vaan ainoat tarjottavat ovat ikuisuuden pyörivä latausrinkula tai error 5xx. Siksi on testattava edes se, että sivusto pysyy ylipäätään pystyssä kävijäpiikin hyökyessä.
Markkinoilla on useitakin kaupallisia ratkaisuja, todella ammattilaistasoa. Kysymys on lähinnä siitä, että ne ovat kalliita ja suurin osa ei ole kohderyhmää. Niitä tarvitsevat sellaiset toimijat, joilla on oma IT-osasto, omat webkehittäjät ja ostettu markkinointiryhmä.
Me kaikki muut tyydymme muihin työkaluihin. Mikä hassuinta, niin niitä hyödyntävät myös kovaa laskutusta tekevät konsultit. Kaupalliset ratkaisut erovat kahdessa suhteessa vapaasti saataviin: ne tekevät käyriä ja piirakoita sekä niissä on enemmän muutettavia tekijöitä. Hassuus loppuu siihen, että suurin osa ei osaa tulkita edes ilmaisten mittareita. Kyllä, minä kuulun enemmistöön.
Miksi maksaa jostain, joka antaa vielä enemmän vaikeita ja ymmärryksen ulkopuolella olevia tunnuslukuja?
Vastaus on, että ei kannatakaan maksaa. Ei ennen kuin ilmaisten tarjoama data lakkaa riittämästä. Siihen pisteeseen pääsy vaatii globaalia ja kova luokan käyntimääriä.
Alkuasetelma
Kaikki mitä minä teen, tapahtuu SSH:ssa root-tunnuksella. Jos kirjaudut omalla tunnuksellasi, niin muista sudo tai su.
Käyttämäni ympäristö on Hetznerin VPS, jossa 4 CPU:ta ja 8 GB muistia. Käyttöjärjestelmänä on Ubuntu 19.10. Palvelimella pyörii Nginx/Varnish/Apache2, jossa on MariaDB. Tukena on objekticachena Redis ja scriptit tekee PHP-FPM.
Käytännössä aivan kaikkea voidaan testata, mutta tavanomaisempaa virtuaaliserverin pyörittäjää kiinnostaa eniten miten muisti riittää. Prosessorin kuorma ei yleensä ole oleellinen. Jos prosessorien takia järjestelmän kuorma on liian suuri, niin joko kyseessä on pahasti alimitoitettu palvelin (jonka taastusti tietää ilman testejäkin) tai jokin koodi on rikki, ja silloin loppuu muistikin, jolloin aletaan metsästämään ongelmaa error.log tai esimerkiksi syslog -logien kautta.
Jos PHP-FPM:ltä loppuu työntekijät joka päivä, niin ei sitä tarvitse erikseen selvittää. Silloin keskitytään PHP-FPM:n asetuksiin. Samaten jos Varnish alkaa nukettamaan cacheaan, niin ei siihen stressitestiä tarvita, vaan annetaan asetuksissa enemmän muistia.
Perusolettamus on, että ympäristö toimii ilman ongelmia normaalitilanteessa ja halutaan tarkastaa mitä tapahtuu, kun tilanne ei ole normaali.
Tilastointi ja valvonta
Ennenkuin kokeilet mitään kuormitus- ja stressiohjelmaa, niin sinulla pitää olla hallussa pari asiaa. Niitä tarvitaan kuormituksen vaikutusten mittaamiseen. Ensisijainen paikka on logit.
cd /var/log
Niissä kiinnostaa eniten Nginxin access.log sekä PHP-FPM:n php7.3-fpm.log.
Varnishin kohdalla riittää varnishstat ja jos MAIN.n.nuked nousee, niin muistia on annettu liian vähän.
Tarvitse jonkun systeemiä valvovan monitorin ja siinä valintasi on Monit.
SSH:ssa komento htop on kuulemma hyödyllinen. ”Kuulemma” siksi, että en ymmärrä mitä siitä pitäisi katsoa.
Muistin kulutuksen sillä hetkellä saa näppärästi selville python-scriptillä ps_mem. Se tulee osassa linux-jakeluja valmiina, mutta tätä kirjoitettaessa ps_mem piti asentaa käsin. Asennus ei ole kuitenkaan kummoinenkaan urakka.
Ensin on selvitettävä, että pythoniin kuuluva pip on asennettuna – luultavasti ei ole, jos et varsinaisesti erikseen pythonin työkaluja asentanut aikaisemmin.
apt install python-pip
Tuota käyttämällä ps_mem pitäisi myös asentua, mutta itse asensin sen perinteisemmällä tavalla. Mutta toki voit kokeilla:
pip install ps_mem
Tämä on tutumpi tapa:
wget https://raw.githubusercontent.com/pixelb/ps_mem/master/ps_mem.py
install ps_mem.py /usr/local/bin/ps_mem
rm ps_mem.py
Komento ps_mem -h antaa helpin ja yksinkertaisella ps_mem komennolla näet kaikki muistia käyttävät prosessit, nimen yhteydessä montako haaraa sillä on ja kuinka paljon muistia on käytössä. Luettelo hyvin selvä, yksinkertainen ja helposti luettava.
Siege
Siege on työkalu, jota käytetään paljon. Sen asentaminen on helppoa:
apt install siege
Ubuntussa ei ainakaan vielä tätä kirjoitettaessa ollut tarjolla uusinta versota (4.0.5), vaan tuli pykälää iäkkäämpi, mutta sen saa Githubista. Tosin silloin Siegen joutuu kääntämään itse. Jos osaat käyttää git komentoa (minä en osaa), niin varmaan tiedät mitä tehdä tälle:
git clone https://github.com/JoeDog/siege.git
Komennolla siege -h saat helpin näkyviin. Komento man siege avaa man-suvun, jossa on enemmän selitetty mitä mikäkin vipu tarkoittaa. Siegen mukana pitäisi löytyä muutama man-sivu lisää, mutta ainakaan minun asentamassani versiossa niitä ei ollut. Voit selata niitä täällä.
Siegessä oli yksi puute. En onnistunut asentamaan sitä Winwows 10:n Ubuntu-appiin. Oikeammin syypää lienee Windows, mutta silti. Jos en asenna erillistä pientä virtuaalipalvelinta Siegeä varten, niin en pääse testaamaan oman boksin ulkopuolelta.
Puutekin on suhteellinen käsite. Jos pitää Siegeä palvelimen testaustyökaluna, ei muuna, niin silloin sitä ei edes tarvitse ajaa ulkopuolelta. Mutta jos yrittää säätää systeemejä aidoille ihmiskäyttäjille, niin Siege antaa liian valoisan kuvan.
urls.txt
Hieman vaihtelevammelle kuormalle kannattaa tehdä url-lista. Sitä käytetään Siegen komennossa vivulla -f urls.txt. En ole kokeillut, mutta uskoisin, että tiedoston nimi saa olla haluttu ja sen sijanti mikä tahansa, kunhan polku kerrotaan. Itse menen siitä mistä aita on matalin ja pidän urls.txt tiedoston Siegen hakemistossa /etc/siege ja ajan aina Siegen samasta paikasta.
Listan rakenne on simppeli. Yksi täydellinen url per rivi. Sitä on mahdollista säätää POST-tietojen, kirjautumisten, headereiten ja cookieiden mukaan. Jos sinulla on tarve moiseen, niin tutustu Siegen manuaaliin.
Ensin ajattelin, että listan teko on aivan pala kakkua. Se varmasti onkin, jos osaa. Minä en osaa. En löytänyt mitään helppoa tapaa harvestoida urleja omilta sivustoiltani niin, että saisin simppelin tekstitiedoston aikaiseksi, mutta bottiliikeenteestä päätellen sen täytyy olla helppoa. En kuitenkaan onnistunut Googlella löytämään mitään helppoa tapaa. Enkä oikeastaan edes vaikeaakaan.
Luulin, että Wgetin logi olisi sellainen. Paitsi että ei ole. Sen siivoamiseen menee tolkuttomasti aikaa. Yritin hyödyntää sitemap-tiedostoa, mutta sieltä olisi pitänyt siivota viimeisin muokkauspäivämäärä pois. Se vaatisi regexin ja parin kehittyneemmän (perus)työkalun osaamista, enkä minä osaa.
Siege tarjoaa työkalun, joka hakee urlit apachen logista.
- kopioi koodi
- tee tiedosto
logparseesimerkiksi hakemistoon/usr/sbinnano /usr/sbin/logparse
Älä yritä tehdä sitä Windowsissa esimerkiksi Notepad++ avulla, koska mukaan tulee joku idioottimainen rivinvaihtojuttujuttu, jonka takia se ei toimi
- Tee siitä suoritettava
chmod u+x /usr/sbin/logparse
- Mene hakemistoon, jossa on Apachen (tai Nginxin) logit
cd /var/log/apache2
Jos sinulla on vastaava setup kuin minulla, Nginx/Varnish/backend, niin prosessoi backendin logi. Fronttina olevan Nginxin logeista et saa sivu-urleja
- Tee
urls.txttiedostologparse -h https://www.example.com -f access.log
- Siirrä (jos on tarpeen)
urls.txtSiegen hakemistoonmv /var/log/apache2/urls.txt /etc/siege/urls.txt
- Kopioi urlit vaikka Exceliin, aakkosta ja poista jaksamisesi mukaan tuplat sekä ns. turhat urlit
Ei tuokaan mikään vaivaton tapa ole.
Käyttö
Itse käytän lähes aina tätä:
siege -c50 -i -b -t1m -f urls.txt
Rotla tarkoittaa, että
- tiedostosta
urls.txtotetaan kokeiltavat osoitteet (-f urls.txt). Jos kokeilet vain yhtä osoitetta, niin laita viimeiseksi url ilman mitään erikoisempia vipuja - simuloidaan 50 yhtä aikaista kävijää (
-c50) - osoitteissa käydään satunnaisessa järjestyksessä (
-i) - pyynnöt tehdään peräkkäin ilman taukoja (
-b) - testi ajetaan minuutissa läpi (
-t1m)
Aidot kävijät eivät moisia sprinttisuorituksia tekisi, mutta tauoton sivujen pyyntö ei anna PHP-FPM:lle aikaa nollailla itseään.
Ajoin yhden testin, jossa tulokset olivat tällaisia:
Transactions: 19872 hits Availability: 100.00 % Elapsed time: 59.71 secs Data transferred: 113.68 MB Response time: 0.14 secs Transaction rate: 332.81 trans/sec Throughput: 1.90 MB/sec Concurrency: 45.12 Successful transactions: 19475 Failed transactions: 0 Longest transaction: 5.90 Shortest transaction: 0.00
Transactionson kuinka monta pyyntöä tai tapahtumaa tehtiin. Jos muuta ei ole, niin se on sama kuinrequests x users, mutta jos käytät url-listaa, et vain yhtä osoitetta, niin joukossa voi olla myös uudelleenohjauksia, ja niistä tulee aina kaksi pyyntöä.Availabilitykertoo kuinka suuri osuus pyynnöistä saatiin palvelimella hoidettua kunnialla vai oliko mukana esimerkiksi timeout-virheitä. Prosentti ei pidä sisällään4xxja5xxvirheitä.Elapsed timeon selvä, kuinka paljon aikaa kului. Jos pakotat testin yhteen minuuttiin vivulla-t1mniin se on tietysti noin minuutti. Muutoin se on aika ensimmäisen pyynnön aloittamisesta viimeisen valmistumiseen.Data transferredkertoo paljonko bittejä siirrettiin. Se pitää sisällään myös http-headerit. Jos käytit url-listaa vivulla-ieli sieltä otettiin sattumanvaraisesti urleja kunnes aika- tai pyyntömäärät täyttyivät, niin siirretty määrä ei tietenkään ole vakio.Response timeon serverin keskimääräinen vastausaika pyyntöihin. Kertoo eräällä tavalla palvelimen nopeuden.Transaction ratekertoo kuinka monta suoritusta, pyyntöä, tehtiin keskimäärin sekunnissa. Se on yksinkertaisestiTransactions/Elapsed time.Throughputon keskimääräinen nopeus millä palvelin on kyennyt siirtämään bittejä sekunnissa käyttäjälle. Yksi arvoista, joiden toivotaan kertovan jotain palvelimen nopeudesta ja tehosta. Aidosti… en ole löytänyt tälle mitään käyttöä, koska ei se aitoa tilannetta kuvaa. Toki, jos se on matala, niin jokin on rikki.Concurrencyon yhtäaikaisten simuloitujen yhteyksien määrä. Kun palvelin alkaa hidastelemaan, eikä saa pyyntöjä alta pois, niin luku alkaa nousemaan. Se ei siis ole sama kuin mitä-cvivulla asetetaan. Esimerkissä testi pakoitettin minuuttiin aitojen urlien kanssa ilman taukoja pyyntöjen välissä, jotenconcurrencyon vain hivenen alle simuloitujen käyttäjien.Successful transactionson kaikki pyynnöt, jotka palauttivat2xxtai3xxtilan, siis <400, eli onnistuneet yhteydet ja uudelleenohjaukset.Failed transactionson pyyntöjen määrä, jonka virhekoodi on 4xx tai 5xx, eli >=400. Se pitää sisällään myös timeoutit ja muut yhteyden epäonnistumiset. Jos url-lista on kunnossa, niin tämän pitäisi aina olla nolla – paitsi, jos teet stressitestiä ja katsot, että kuinka usein serveri kompastuu todella kovalla kuormalla.Longest transactionon pisimmän ajan vienyt pyyntö. Ei saisi tulla, mutta aina tulee. Kun löytyy hidas, kuten esimerkissä yli 5 sekuntia, niin sen alkulähdettä kannattaa alkaa selvittämään. Usemmiten syy on jokin ulkoinen API-pyyntö tai vastaava, kuten Googlen palvelut, tai WordPressissä esimerkiksiadmin-ajax.phptai Jetpackin palvelut. Laita komentoon mukaan-vniin saat listan miten eri pyynnöt vastasivat.Shortest transactionon nopeimmin suoritettu pyyntö. Aika turha mittari minusta. Jos sekin vie paljon aikaa, niin tiedetään jo valmiiksi, että sivustolla on joku rikki. Se ei nimittäin saisi pidentyä huomattavasti edes kovissa kuormissa, koska aina sieltä alkupäästä joku saadaan tehtyä vauhdikkaasti.
Siegeä voi yrittää käyttää myös simuloimaan aidompaa webkävijää. Muutetaan hieman komentoa:
siege -c50 -r1 -d10 -f urls.txt
50 yhtäaikaista käyttäjää (-c50), joille arvotaan osoite tiedostosta urls.txt (-f urls.txt). Sallitaan yksi toisto (-r1) ja pyyntöjen välillä on satunnainen tauko 0 – 10 sekuntia (-d10).
Tulos oli:
Transactions: 2488 hits Availability: 100.00 % Elapsed time: 20.03 secs Data transferred: 14.41 MB Response time: 0.19 secs Transaction rate: 124.21 trans/sec Throughput: 0.72 MB/sec Concurrency: 23.83 Successful transactions: 2438 Failed transactions: 0 Longest transaction: 5.25 Shortest transaction: 0.00
Käytännössä mikään ei siis oleellisesti muuttunut. Heti testin alussa PHP-FPM:n prosessit kävivät maksimilla ja palautuivat noin sekunnissa takaisin lähtöarvoihinsa. Mutta PHP-FPM:n logeista sen sijaan löysin reaktion:
WARNING: [pool www] seems busy (you may need to increase pm.start_servers, or pm.min/max_spare_servers), spawning 8 children, there are 0 idle, and 17 total children
Ongelma on siinä, että en saanut toistettua tuota. Joten olettamus olisi, ehkä, että koska tein testin live-saitille (jota aidot ammttilaiset eivät koskaan tekisi), niin ehkä paikalla oli samaan aikaan ihmiskävijöitä sen verran, että kuorma riitti virheeseen. Joka tapauksessa sain tuosta yhden mitta-arvon lisää pohtia PHP-FPM:n asetuksia.
Kokeilin vielä yhtä muunnosta:
siege -c100 -d10 -r1 https://www.katiska.info/tieto/
Tulos oli:
Transactions: 5500 hits Availability: 100.00 % Elapsed time: 29.34 secs Data transferred: 99.16 MB Response time: 0.26 secs Transaction rate: 187.46 trans/sec Throughput: 3.38 MB/sec Concurrency: 49.20 Successful transactions: 5400 Failed transactions: 0 Longest transaction: 6.89 Shortest transaction: 0.00
Sama juttu, tulokset eivät sinällään muuttuneet mitenkään oleellisesti. Mutta taas PHP-FPM:n logeista löytyi tuttu ilmoitus:
WARNING: [pool www] server reached pm.max_children setting (20), consider raising it
Ja kuten edellisessä, niin en saanut virhettä toistettua, vaikka ajoin niitä uudestaan vuorotellen. Mutta silti tuo antaisi ymmärtää, että nykyiset PHP-FPM:n asetukset
pm = dynamic pm.max_children = 20 pm.start_servers = 2 pm.min_spare_servers = 2 pm.max_spare_servers = 20 pm.process_idle_timeout = 10s; pm.max_requests = 500
saattavat olla liian hilkulla. Tosin, päivää aikaisemmin kiireisimmällä sivustolla oli useamman tunnin yli 100 yhtäaikaista käyttäjää ilman ongelmia. Ja tässä päästään reverse proxyn ihanuuteen. 80 % niistä vieraili samassa osoitteessa lukien samaa välimuistista tulevaa juttua. Kuorma oli lähellä nollaa.
Lifting the server siege…Segmentation fault (core dumped)
Saatat saada virheilmoituksen Lifting the server siege...Segmentation fault (core dumped) ja Siege keskeyttää toimintansa. Yleisimmät syy ovat
- jostain urlista puuttuu päättävä kauttaviiva
/ - joku url antaa
error 404 - Siege ei vaan toiminut
Minulla kyse on ollut aina viimeisestä. Siihen on auttanut useimmiten simuloitavien käyttäjien määrän vähentäminen tai sitten olen pitänyt tauon ja yrittänyt uudelleen.
ApacheBenchmark
ApacheBenchmark on vanha apuohjelma ja ilmeisesti sitä ei enää päivitetä. Silti se toimii ja sitä myös käytetään paljon. Se ei välttämättä kuulu serverin vakiovarustukseen, mutta asentaminen on helppoa;
apt install apache-utils
Löydät virallisen manuaalin täältä, mutta toki ab -h ja man ab antavat riittävästi tietoa, ainakin kokeiluun.
ApacheBenchmarkia saat ajettua myös ulkopuolelta oman virtuaaliserverisi. Useimmiten teen testit ensin serverillä ja sitten käynnistän windows 10-läppärin Ubuntu appsin ja kokeilen sieltä samaa. Saan edes häivähdyksen siitä todellisuudesta, jonka aidot käyttäjät kokevat.
Käyttö
Useimmiten esimerkkinä käytettävä komento on tämä:
ab -k -n 10000 -c 100 https://www.example.tld/
- kokeiltava url on
https://www.example.tld - 100 yhtäaikaista simuloitua käyttäjää (
-c 100) - tehdään 10000 GET pyyntöä (
-n 10000) - käytetään HTTP:n KeepAlive tapaa (
-k)
Tässä on yksi tulos sivustolta katiska.info:
Document Path: /tieto/
Document Length: 119114 bytes
Concurrency Level: 100
Time taken for tests: 9.541 seconds
Complete requests: 10000
Failed requests: 0
Keep-Alive requests: 9948
Total transferred: 1199109740 bytes
HTML transferred: 1191140000 bytes
Requests per second: 1048.07 [#/sec] (mean)
Time per request: 95.414 [ms] (mean)
Time per request: 0.954 [ms] (mean, across all concurrent requests)
Transfer rate: 122729.41 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 15.4 0 161
Processing: 2 93 83.4 71 765
Waiting: 1 69 66.9 52 721
Total: 2 95 84.8 71 765
Percentage of the requests served within a certain time (ms)
50% 71
66% 99
75% 122
80% 139
90% 207
95% 263
98% 349
99% 415
100% 765 (longest request)
curl -I -0 --http1.1 https://www.example.tld/
Jos/kun vastausHTTP/1.1 200 OKniin kaikki on hyvin. Jos ei, niin ahkerasti KVG.2xxtai uudelleenohjaus, esimerkiksi301, kuten404tai501Complete requests/Time taken for tests– se eräällä tavalla kuvaa palvelimen tehoa ja nopeutta vastata pyyntöihin. Se ei palvele kävijää mitenkään, koska häntä ei kiinnosta miten muilla menee. Sen sijaan se saattaa antaa webmasterille yhden numeron lisää mietittäessä, että pitäisikö palvelinta skaalata jollain tavalla.Time per request(1.) on jokaisiin pyyntöihin mennyt yhteenlaskettu aika jaettuna kaikilla pyynnöillä eli yhden pyynnön keskimääräinen aika.- Molemmat
time per requestajat ovat keskiarvoja, hieman eri tavalla laskettuja. Ne ovat eräällä tavalla keskimäärin nopeimpia mahdollisia aikoja millä pyyntö saadaan toteutettua. Siksi niiden kanssa täytyy olla hieman varovaisia, koska yksikin hidastelu heikentää keskiarvoa, vaikka 90 % muista pyynnöistä menisikin paljon nopeammin. Samaten välimuistit voivat vaikuttaa tilanteeseen. Näitä kannattaa aina miettiä yhdessäconnection timestaulukon kanssa. Time per request(2.) =Time taken for tests/Complete requestsja toinen löytämäni selitys onconcurrency * timetaken * 1000 / complete requests– keskimääräinen aika missä asiakas on saanut pyynnön valmiiksi; kuinka nopeasti palvelin toimii. Tai jotain. En aidosti ymmärrä lukua. Puolet pyynnöistä on vienyt 71 ms tai alle, ja nyt sitten yhtä äkkiä keskimääräinen aika olisi 0,954 ms.Transfer rate=HTML transferred/Time taken for tests– kuinka nopeasti HTML-tieto on keskimäärin saatu siirrettyä palvelimeltaConnection Timeskertoo pyynnön eri osa-alueiden kestot. Niistä saattaa saada hiukan lisäapua pähkäiltäessä missä pullonkaula on.Connect time: aika, joka kestää aukaista socketProcessing time: first byte + siirtoWaiting: aika first byteenTotal:Connect+Processing
Percentage of the requests served within a certain timekertoo montako prosenttia pyynnöistä on vienyt määrätyn ajan. Omassa esimerkissäni puolet on selvinnyt 71 millisekunnissa tai alle. Pyynnöistä 90 % on suositettu 207 sekunnissa tai nopeammin. Hitain aika on ollut 765 ms.
Taulukko kertoo periaatteessa sen mahdollisuuden kuinka usein kävijä törmää hitaaseen pyyntöön. Niistä, tai muutoin, täytyy päättää miksi olisi hitain hyväksyttävä aika. Satunnaisia hidastuksia tulee aina, joten itse vedän rajan siihen mitä 80 % kävijöistä on saanut.
Kaava1 — T^n, jossaTon rajaksi päätetty prosentti (desimaaleina) janon pyyntöjen määrä, kertoo prosentuaalisen todennäköisyyden millä kävijä törmää hitaaseen pyyntöön. Minulla se olisi vaikkapa 14 pyynnöllä silloin 1-(0,80^14)=0,956=95,6 % todennäköisyydellä ainakin yksi pyyntö veisi kauemmin kuin 139 ms. Jos otetaan anteeksiantavampi tavoite, eli 95 % pääsisi 263 ms hitaimmalla pyynnöllä, niin todennäköisyys sille olisi 14 pyynnöllä niin 51 % kävijöistä saisi ainakin kerran jossain kohtaan hitaammin kuin 0,263 sekuntia latautuvan osan sivusta. Se on aika korkea osuus ja työ alkaisi siitä, että tavalla tai toisella pitäisi selvittää, että mikä hidastaa ja voiko sille tehdä jotain. Tosin, 263 ms on itsessään aika nopea.
Laitetaan vertailuksi virtuaalipalvelimen ulkopuolelta tehty sama testi. Pyynnöt tulevat omasta wlanista Elisan mobiiliverkon läpi Frankfurtissa sijaitsevalle serverille.
Concurrency Level: 100
Time taken for tests: 113.568 seconds
Complete requests: 10000
Failed requests: 0
Keep-Alive requests: 9927
Total transferred: 1199109635 bytes
HTML transferred: 1191140000 bytes
Requests per second: 88.05 [#/sec] (mean)
Time per request: 1135.684 [ms] (mean)
Time per request: 11.357 [ms] (mean, across all concurrent requests)
Transfer rate: 10311.01 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 16 280.3 0 18743
Processing: 223 1034 808.0 905 42003
Waiting: 107 450 369.0 392 14343
Total: 223 1050 994.5 907 60746
Percentage of the requests served within a certain time (ms)
50% 907
66% 1062
75% 1194
80% 1277
90% 1509
95% 1788
98% 2375
99% 2888
100% 60746 (longest request)
Ero on huimaava. nyt ei enää 95 % pyynnöistä suoriutunutkaan 263 millisekunnissa tai nopeammin, vaan aikaa menikin 1788 ms eli vajaa 1,8 sekuntia. Puolet pyynnöistä käsiteltiin hieman alle sekunnissa. Ainakin periaatteessa.
Periaatteessa siksi, että keskiarvona yhden pyynnön käsittelyyn netin yli meni noin sekunti. Haarukka oli kuitenkin suuri, alkaen 223 millisekunnista ja kaikkien pyyntöjen puoliväli oli ajassa 907 ms. Se mikä oli huolestuttavaa, tai ainakin mietityttävää, oli yksi pyyntö, joka kesti yli minuutin valmistua.
Kumpaa tapaa sitten kannattaa käyttää? Minun mielestäni molempia, mutta serverin säädöt tehdään ensin ”sisäisellä” testillä. Jos muistia on hiukan kitsaasti, niin sitten tingataan sen mukaan mitä ”ulkoinen” antaa.
Jatkuva kuorma
ab tekee pyydetyn määrän pyyntöjä ilman taukoja yksi toisensa jälkeen. Kun pyyntömäärä on täynnä, niin testi on loppu. Joskus olisi kuitenkin hyvä tietää mitä tapahtuu, jos kuorma jatkuukin pidempään.
ApacheBenchmark ei tarjoa sitä suoraan, mutta sille on olemassa kiertotie (ainakin Ubuntussa). Laita alkuun komento watch -n 1 niin ab:n komento toistuu kerran sekunnissa. Esimerkiksi näin:
watch -n 1 ab -k -n 2500 -c 25
Oma työnkuva
Minä en ole hyvä esimerkki siitä miten palvelimen kuormitusta mitataan ja miten sitä säädetään. Tiedän aiheesta aivan liian vähän. Mutta… jos pyörität vain sivustoja, niin sen suurempaa ymmärrystä ei edes tarvita. Riittää, että palvelin tekee työnsä riittävän jouheasti käyttäjien näkökulmasta. Asia muuttuu, jos pyörität jotain muuta palvelua ja varsinkin kaupallista. Mutta silloin ollaan tilanteessa, että kuormituksen mukaan mietitään myös load balancereita, skaalautumista ja muita isojen poikien juttuja. Eikä serverit ole mallia 4 CPU:ta 8 gigan RAM:lla.
Lähestymistapani on hyvin ongelmakeskeinen. WordPressissä käyttämäni teema, sekä muut ratkaisut, olivat niin raskaita, että en saanut nopeuden hiventäkään aikaiseksi, enkä halunnut muuttaa sinällään mitään, niin ensin otin käyttöön WordPressissä sivucachen ja sen hoiti WP Rocket. Se nopeutti reippaasti. Silti halusin vielä lisää ja taas sekunti hävisi Varnishin avulla.
Silti kuorma kasvoi. varsinkin verkkokurssien myötä. Kun webhotellit eivät riittäneet ja virtuaalipalvelimellakin alkoi kuorma olla niin suuri, että 3000 kävijällä päivässä olisin tarvinnut 6 CPU/16 GB, niin aloin katsella tarkemmin mitä oikein tapahtui. Huomasin, että 80 % liikenteestä tulikin ihan muualta kuin ihmiskävijöiltä. Botit painoivat serveriä polvilleen. Opettelin miten botit ja crawlerit estetään Fail2banilla. Tehostin sitä Varnishin avulla ja lopulta aloin pysäyttämään ne jo serverin kynnyksellä.
Hetken aikaa kaikki oli hyvin, kunnes heräsin omituisiin ja satunnaisiin miettimisiin. Vilkaisin logeja ja huomasin PHP-FPM:n logeissa omituisia virheitä, joita en ymmärtänyt. Uuden asian opettelu ja sen jälkeen alkoikin PHP-FPM:n säätäminen. Siihen tarvitsin hieman enemmän tietoa siitä missä menee virtuaalipalvelimeni rajat. Säädin ensin resurssien käytön nettiohjeiden mukaan. Ongelma oli sama kuin nettiohjeissa aina: ne kopioivat toinen toisiltaan samaa asiaa, joka perustuu yhteen ja vain yhteen olettamukseen. PHP-FPM:n kohdalla oletus oli, että Nginx hoitaa webpalvelimen sellaisenaan. Edes PHP-FPM:n käyttöä tilanteessa, että se toimii reverse proxyna, ei esitelty mitenkään. Moinen mahdollisuus mainittiin vain sivulauseessa.
Minulla oli Nginx keulilla, Varnish välissä ja Apache2 backendinä. 8 gigan rammilla PHP-FPM:n säätäminen ohjeiden perusteella tarkoitti sitä, että muisti vietiin Varnishilta ja varattiin PHP-FPM:n käyttöön – joka ei tehnyt sillä mitään, koska Varnish hoiti asian eli tappoi välimuistina kävijäpiikkien PHP-kuorman. Minulla suurin kuorma ei tule kävijöiltä, vaan kello 4 aamuyöllä tehtävästä sivustojen täydestä backupista. Siinäkään tehokkain tehohuippujen tasaaja ei ollut PHP-FPM:n asetukset, vaan cronin säätäminen ja backuppien porrastaminen.
Kun palvelimen kurmitusta mitataan, niin siinä mitataan aidosti aina kahta asiaa:
- miten webpalvelin ylipäätään suoriutuu tehtävästään
- miten PHP suoriutuu tehtävistään
Koska palvelinpuolta hinkataan kohdalleen aivan eri tavalla, niin loppujen lopuksi kuormituksella haetaan PHP:lle tehokkainta muistinkäyttöä PHP-FPM:n kautta, ja jos se ei onnistu, niin silloin hankitaan isompi siivu virtuaalipalvelinta. Samalla sitten tuppaa korjaantumaan muutkin pahimmat pullonkaulat, ainakin silloin kun pahin hidaste ei olekaan tekniikka miten websivut on tehty.
Käyttämäni mittarit
Käytän nykyään pelkästään ApacheBenchmarkia. Osaksi siksi, että ymmärrän hieman sen tuloksia, mutta Siegellä en ole saanut aikaiseksi mitään minua hyödyntävää.
Minulle kävijäpiikki tarkoittaa sataa yhtäaikaista kävijää. Yleensä testaamaltani sivustolla tulee 15 – 20 pyyntöä (requestia), jos kävijä on käynyt siellä aikaisemminkin. Pidin tuota, 100 kävijää x 20 pyyntöä = 2000 pyyntöä, vertailuasetelmana eli komensin kuomitetuimmalla sivustolla:
ab -k -n 2000 -c 100 https://www.example.tld/joku-aito-sivu/
Saat helposti selville montako requestia sivullesi lähetetään. Avaa selaimen developer-tila/web-työkalut ja valitse network/verkko. Kun lataat jonkun sivun, niin näet esimerkiksi Firefoxin sivun alareunassa montako requestia tapahtui.
Otin lähtöarvoksi sen ajan, joka kattoi 99% pyynnöistä (aidossa testissä 440 ms). Koska testasin live-sivustoa, niin toki tulokseen vaikutti oleva liikenne, mutta valitsin ajankohdan, jolloin siellä oli vain ns. tyhjäkäyntiliikennettä; se määrä kävijöitä, joita yleensä tulee koko ajan hakukoneiden ja vanhojen jakojen kautta ilman uutta julkaisua.
Tuplasin molempien määrän, kunnes alkuperäinen 99% arvo oli painunut 50 % kohdalle. Testissäsi se tuli vastaan pyynnöillä 16000 ja samanaikaisilla käyttäjillä 800. Silloin pyyntöjen suorittamisen keskimääräinen kokonaisaika (Connection times: Total) oli 860 ms. Pystyisin elämään sen kanssa, koska 800 samanaikaisessa käyttäjässä menisi itse määräämäni teoreettinen aika sille, että palvelin hoitaisin vielä hommansa riittävän hyvin.
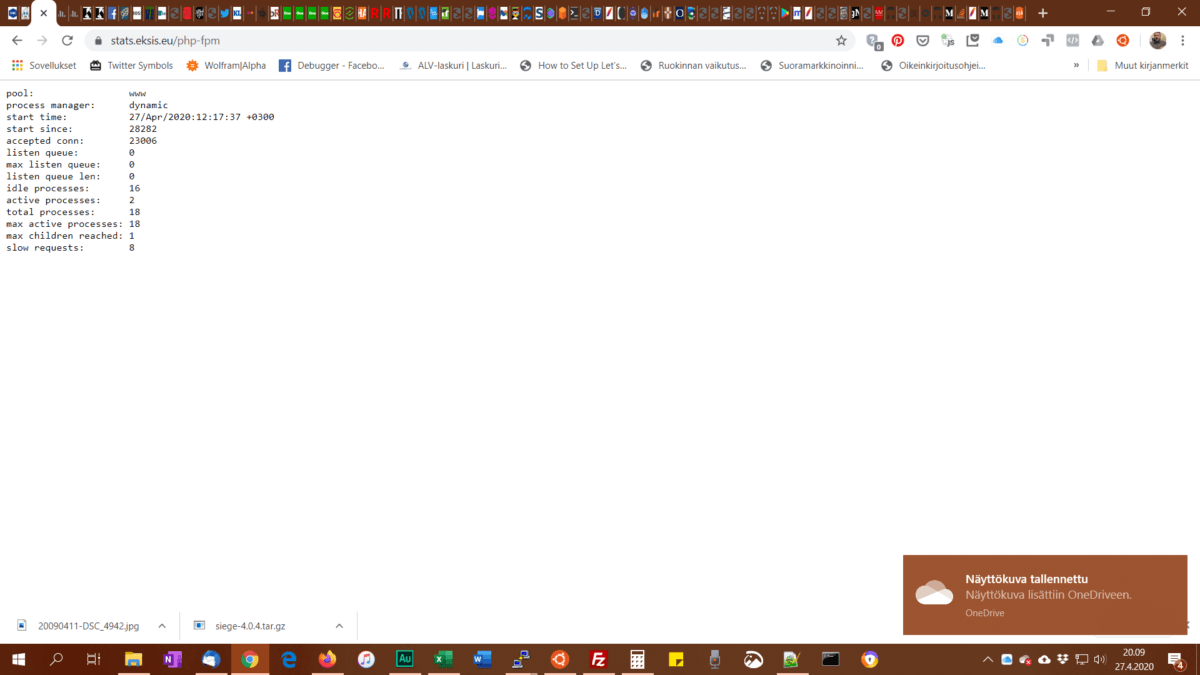
Seuraavaksi kokeilin miten molemmat arvot käyttäytyvät PHP-FPM:n kanssa. Olin asettanut max_children arvoon 18 ja start_servers arvoon 2 ja pm = dynamic. Hyvin vaatimattomiksi siis. Testaaminen oli simppeliä. Laitoin ab:n töihin ja taoin F5:ttä PHP-FPM:n status-sivulla.
-n 2000 -c 100: active processes: 2 (normaalisti 1)-n 16000 -c 800: active processes: 2 (satunnaisesti testin aikana, normaalisti 1)
Tuo tarkoittaa sitä, että välimuisti tekee tehtävänsä, enkä tarvitse testin perusteella yhtään enempää muistia PHP-FPM:lle varalle.
Mutta entä kun paikalle tulee ensikertalaisia? Niitä on tuolla sivustolla noin 60 prosenttia kävijöistä, eikä heillä ole mitään selaimen välimuistissa. Silloin pyyntöjen määrä on lähes kymmenkertainen, noin 160. Se on sama kuin ylärajaksi määrittelemäni 16000 pyyntöä, mutta vain sadalla yhtäaikaisella käyttäjällä, joten ongelmaa ei ole. Tein kuitenkin testin ja pyyntöjen nostaminen 16 tuhanteen aiheutti sen, että 98 % sai rajaksi asettamani noin 440 ms.
Nyt tiedän mikä on testien perusteella mitta-arvo palvelimen suorituskyvylle ja tiedän missä vaiheessa teoriassa palvelimen rajat alkavat vaikuttamaan. Silti on syytä testata asioita myös aidon käyttäjän näkökulmasta, sillä testit eivät sitä koskaan tee.
